应用于分离式内存的ROLEX技术
哈哈, 赶了半天ddl被放鸽子了, 科研课堂也就图个乐.
ROLEX方法的提出动因
在分离式内存 (disaggregated memory) 中, 使用树形结构来索引有序键值的效果和性能都不尽人意.
XStore系统首次将智能索引 (learned index) 技术引入到分布式储存, 解决了树形结构的不足. 但对于动态的workload, XStore只能依赖于集成的内存系统.
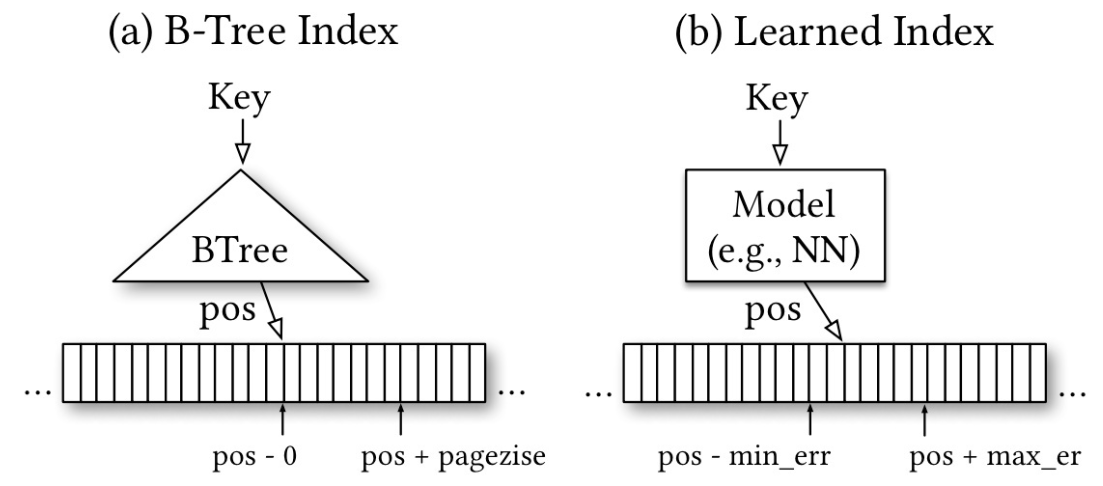
对XStore进行改进以适用于分离式内存: XStore-D, 但效果仍不理想. 主要有以下原因:
- 内存节点 (memory node) 的算力不足.
- 如果将计算工作转移到计算节点 (compute node), 需要使用巨大的网络带宽.
- 不同节点间存在不一致的问题.
为了解决以上种种问题, 论文提出了ROLEX方法.
ROLEX方法的主要内容
数据插入与模型训练解耦
传统方案:
- 插入数据后, 对数据集重新排序
- 将新的数据集传送到计算节点重新训练模型
- 将新的模型同步到所有节点
ROLEX的方案:
对算法和模型改进后, ROLEX能实现以下功能:
新数据可以直接插入到内存节点.
即使插入了适量新数据, 模型无需重新训练也能继续正确索引.
插入的新数据较多时, 模型在内存节点就可以完成重新训练, 无需再传送到计算节点.
实现方法:
向分段线性回归模型 (PLR) 中加入偏移量, 使得插入新数据后仍能索引数据.
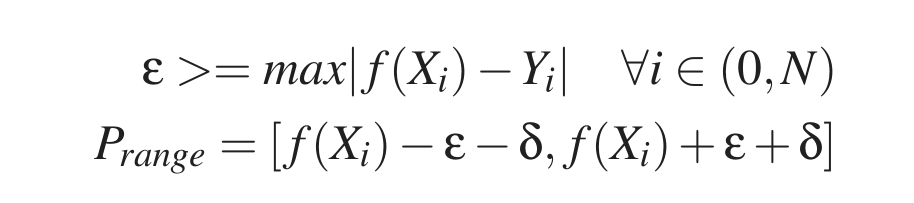
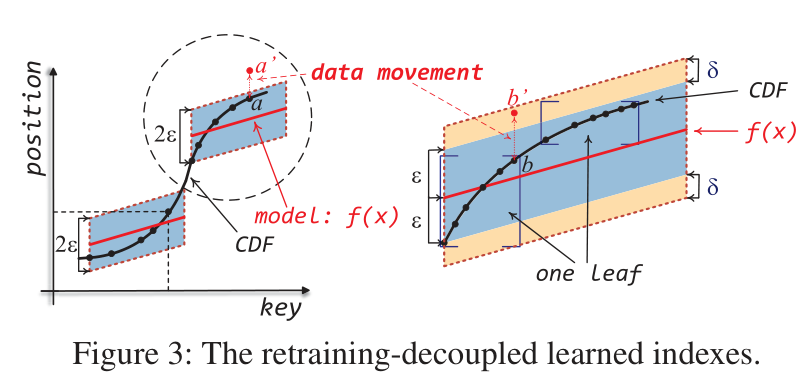
数据只能在固定大小的数组区域移动, 查询数据时返回数据的所在区域 (leaf). 这样保证了数据不会丢失.
当某个leaf的容量不够时, 在相同的位置添加一个synonym-leaf. leaf和对应的synonym-leaf使用指针连接.
这三个限制条件使得新插入的数据仍在之前预测过的范围之内, 模型不需要重新训练也能找到新插入的数据.
ROLEX系统的组织结构
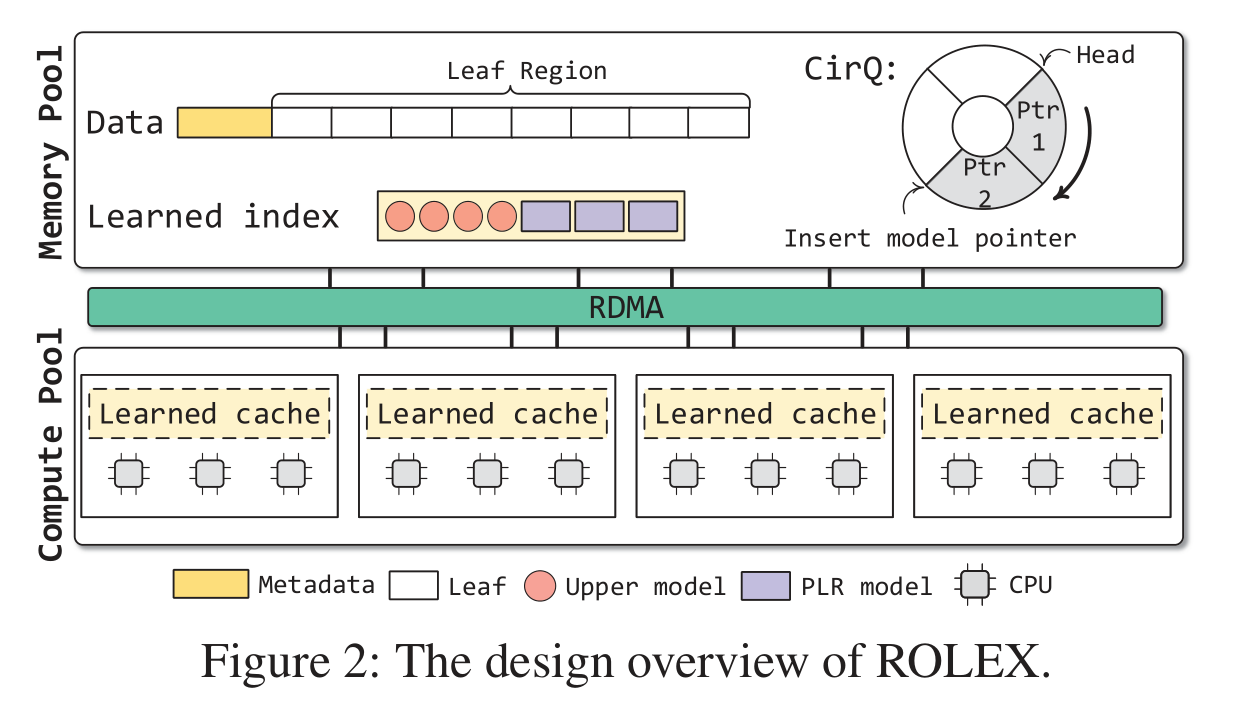
Leaves
leaves储存在Leaf Region里. Leaf Region之前紧邻的8B储存leaves的个数 (alloc_num) 和能储存的最大数目.

Upper models
Upper models通过最小键集 (the smallest keys) 进行训练, 用来索引下层的PLR模型.
PLR models
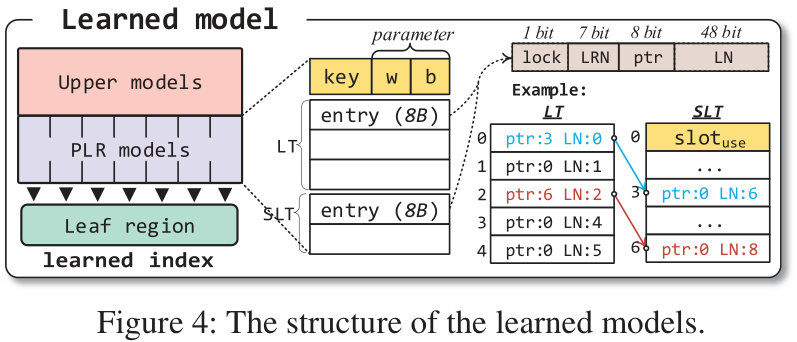
PLR模型由最小键集, 参数, 和leaf teble (LT) 和 synonym leaf table (SLT)组成.
LT和SLT储存8B的entries. 每一条entry由1 bit的lock位, 7 bits的leaf region, 8bits的指针和48 bits的leaf number组成. SLT的第一项用于记录已经写入的entry数量 ($slot_{use}$).
LT的大小在训练模型时决定, SLT的大小固定为$2^8$个entry.
CirQ
ROLEX会维护一个环形队列 (CirQ) 来储存重新训练后加入的新模型.
Learned cache
Learned cache位于计算节点: 计算节点会将索引模型缓存到自身.
单边索引操作 (One-sided Index Operations)
单边索引操作都是在计算节点完成的.
点查询
点查询数据时, 会先用索引模型找到leaf在LT或SLT中的位置, 再根据下方的公式计算出leaves的实际地址. 最后使用doorbell batching的方式在leaves中找到数据.
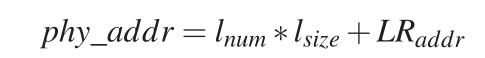
范围查询
在进行[K, N]查询时, 会额外查询相邻的$N/\delta$个leaf. 仍然使用doorbell batching的方式查询leaves.
插入
先用点查询的方式找到相应的leaves, 然后将lock位设为1 (通过CAS), 插入数据, 最后将lock位设回0, 并将alloc_num和$slot_{use}$加上1 (通过FAA).
更新
与插入类似, 同样先用点查询的方式找到对应的数据, 然后检查数据是否为最新, 如果不是则进行替换.
删除
与插入和更新类似. 但删除某个数据时不改变其它数据的排列, 以确保预测模型在重新训练前仍能使用.
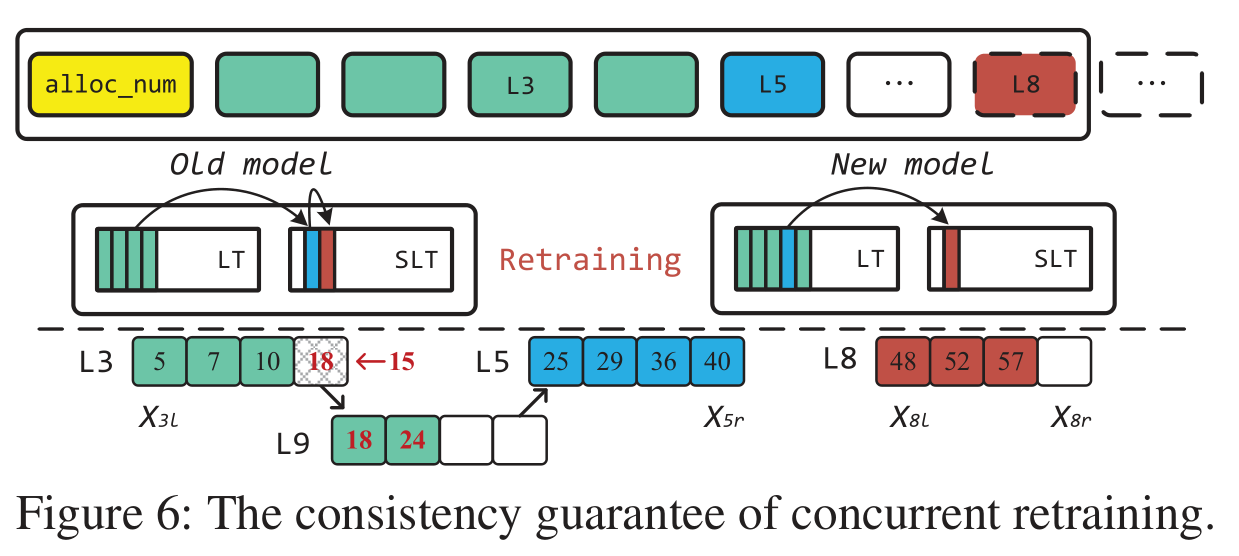
模型异步重新训练 (Asynchronous Retraining)
当SLT的容量即将不足以容纳新数据时 (事实上是在距离完全填满还有$2^7-1$个slot时), 内存节点会异步重新训练模型.
为了保证一致性, 在重新训练模型时, 不会直接阻塞计算节点的操作. 计算节点会通过对比旧的LT, SLT和新的LT, 将数据重定向到新的SLT, 从而避免不一致现象的发生.
ROLEX方法的性能分析
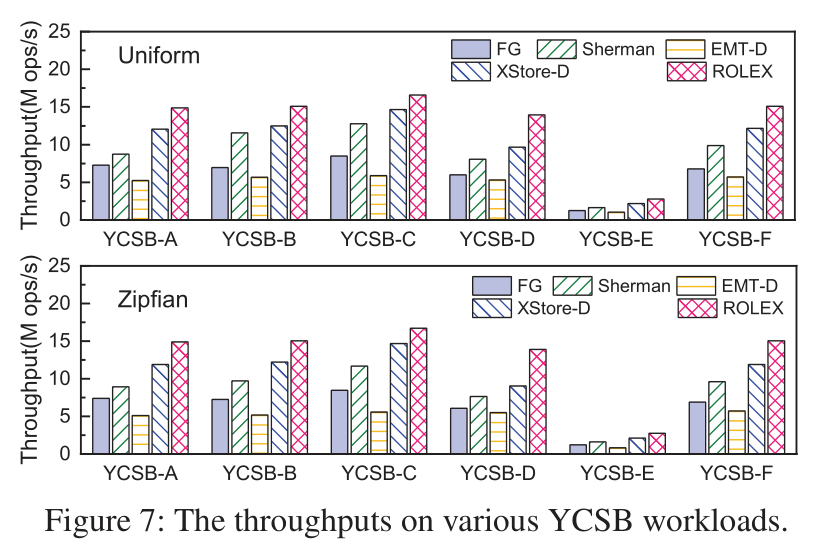
- 在不同的YCSB workload中, 与其它方法相比, ROLEX方法的吞吐量都有明显优势.
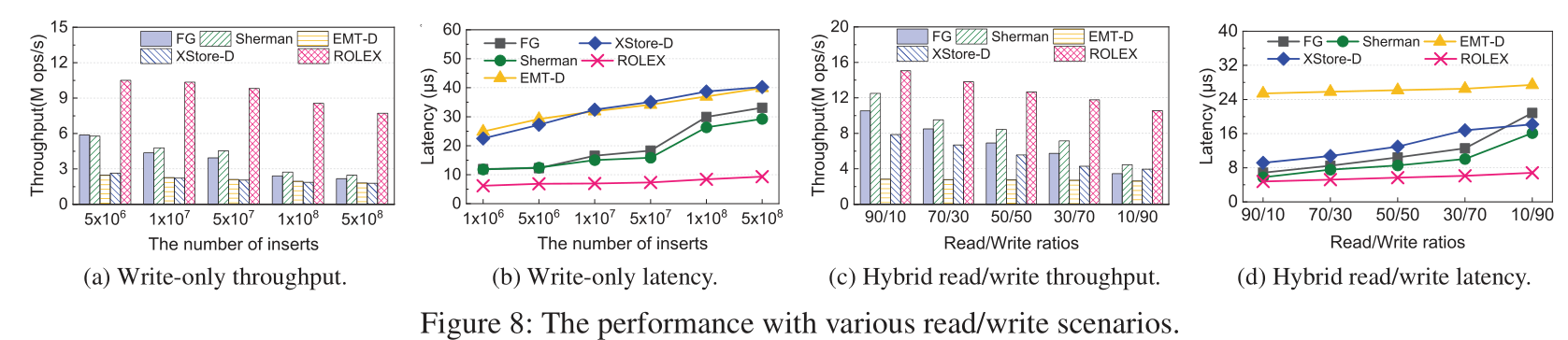
- 在其它情况中, ROLEX方法的大吞吐量和低延迟都有明显优势.
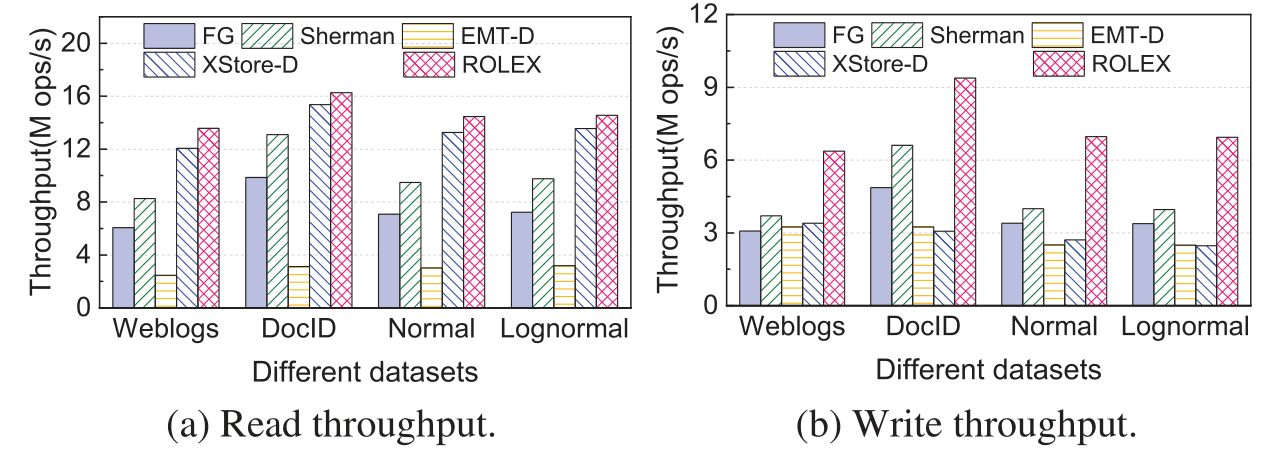
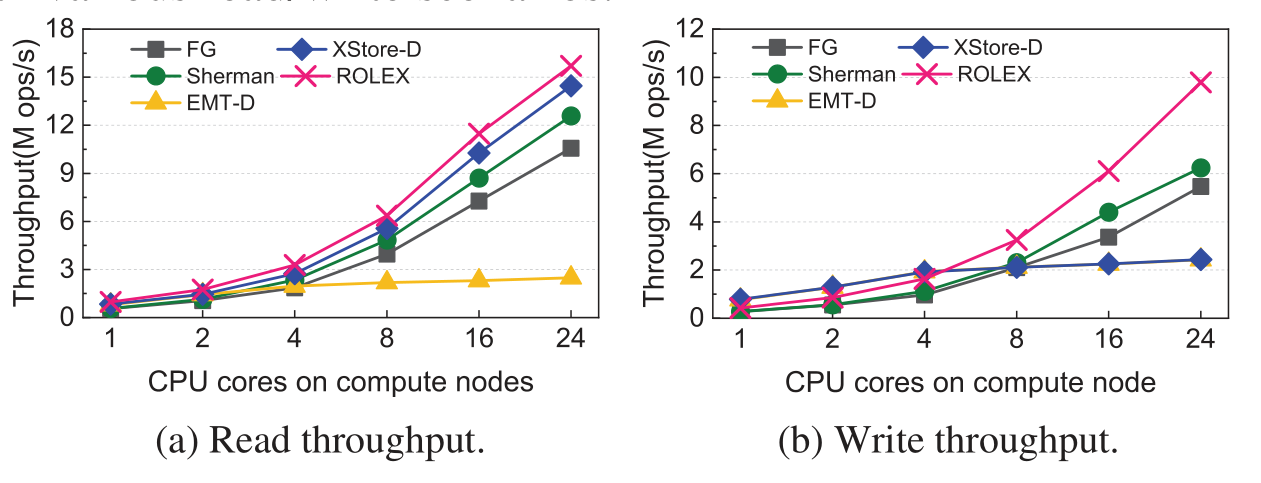
- 对于分离式内存系统, 即CPU资源有限的情况下, ROLEX方法的可扩展性也优于其他方法.
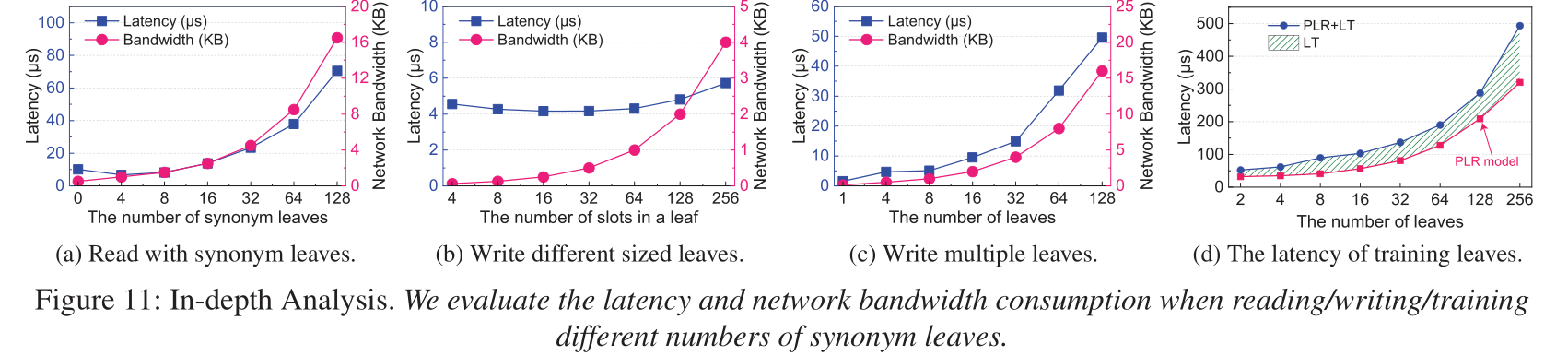
- ROLEX虽然训练模型的延迟略高, 但读写数据的延迟很低.
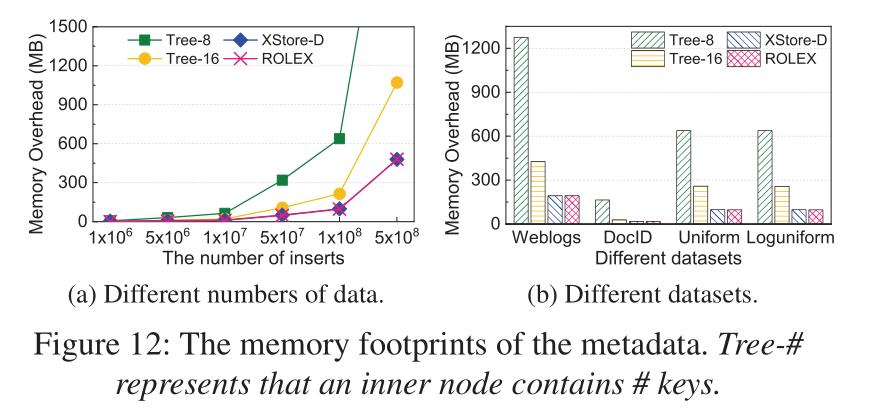
- ROLEX的内存开销要明显优于传统的树形结构.
应用于分离式内存的ROLEX技术